Summary
- Mostly followed the original BERT
- Excluded NSP task, NSP loss isn’t necessary.
- Dynamic masking is slightly better than static masking (actually.. almost no difference)
- RoBERTa is just a BERT configuration, and performs much better than the original one.
- Training longer, with bitgger batches and more data is desirable.
Essentially, RoBERTa is just a reconfiguration BERT. Then why this is important?-
- Revealing the importance of pretranining strategies
- Eliminating the NSP task
- Larger batch sizes and training data matter
- Dynamic masking for MLM
Introduction
This is a replication study of BERT.
- Found that BERT was significantly undertrained.
- Proposed an improved recipe for training BERT models: RoBERTa
Modifications (from the original one)
- (1) Training the model longer (with bigger batches, over more data)
- (2) Removing the NSP(next sentence prediction) objective
- (3) Training on longer sequences
- (4) Dynamically changing the masking pattern
Contributions
- (1) Presented a set of important BERT design choices and training strategies.
- (2) Used a novel dataset (CC-News), and confirm that using more data for pre-training further improves performance on downstream tasks.
- (3) Showed that MLM pretraining is competitive.
Experimental Setup
Implementation
- Mostly followed the original BERT setting
- “Didn’t randomly inject short sequences” → Because NSP task wasn’t used, so no negative samples are needed.
Training Procedure Analysis
Which choices are important for pretraining BERT models?
Static vs. Dynamic Masking
Static masking
- The original BERT masks only once during preprocessing → single static mask.
- To avoid using the same mask, duplicated training data 10 times → 10 different ways of masking (over 40 epochs).
Dynamic masking
- Generate masking pattern every time a sequence is fed to the model.
Results
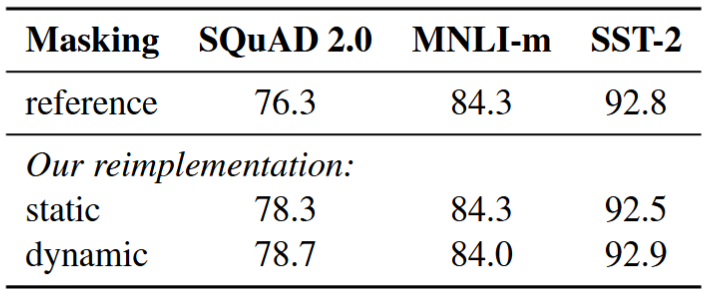
- Dynamic masking is slightly better than static.. (but actually, almost no difference)
Model Input Format and Next Sentence Prediction
Is NSP really important?
- The original study said NSP loss was crucial, but some recent works have questioned the necessity.
Comparison results
- asdf
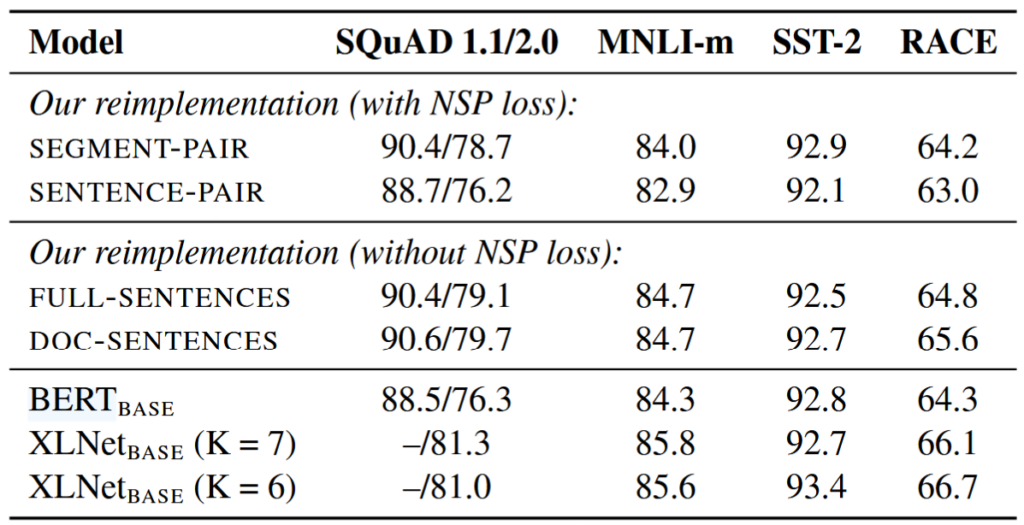
Using individual sentences hurts performance on downstream tasks
(better to use related sentences)
Removing the NSP loss matches or slightly improves downstream task performance
- Then, why did the original BERT said it’s important?
- BERT just removed the loss itself, and still remained SEGMENT-PAIR format..
- Suitable format for suitable loss!
Training with large batches
- Large batch size improves perplexity
RoBERTa
(Robustly optimized BERT approach)
Configurations
- Dynamic masking
- FULL-SENTENCES without NSP loss
- Large mini-batches
- Larger byte-level BPE
- architecture: \( text{BERT}_{\text{LARGE}} \)
Results
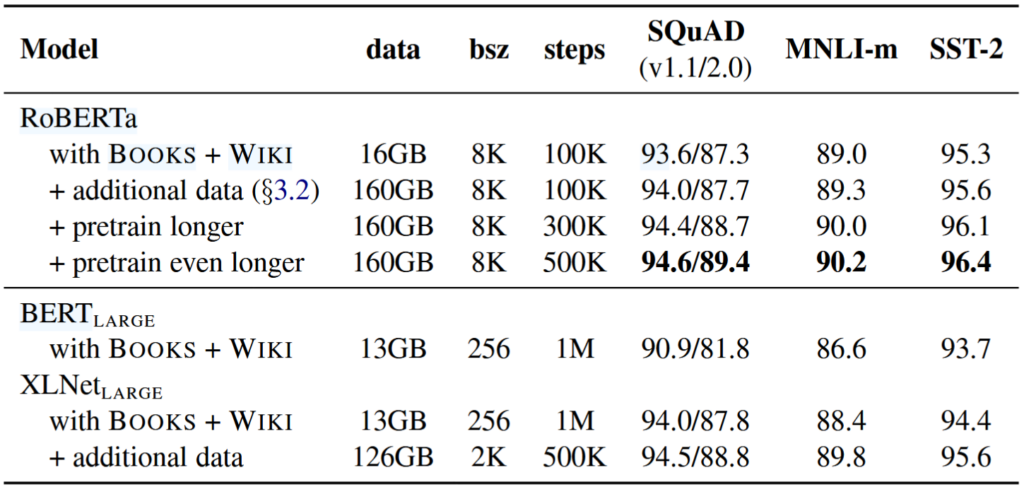
- Large improvements!
- Increasing the number of pretraining steps (100K → 300K, 500K) was better for downstream tasks.