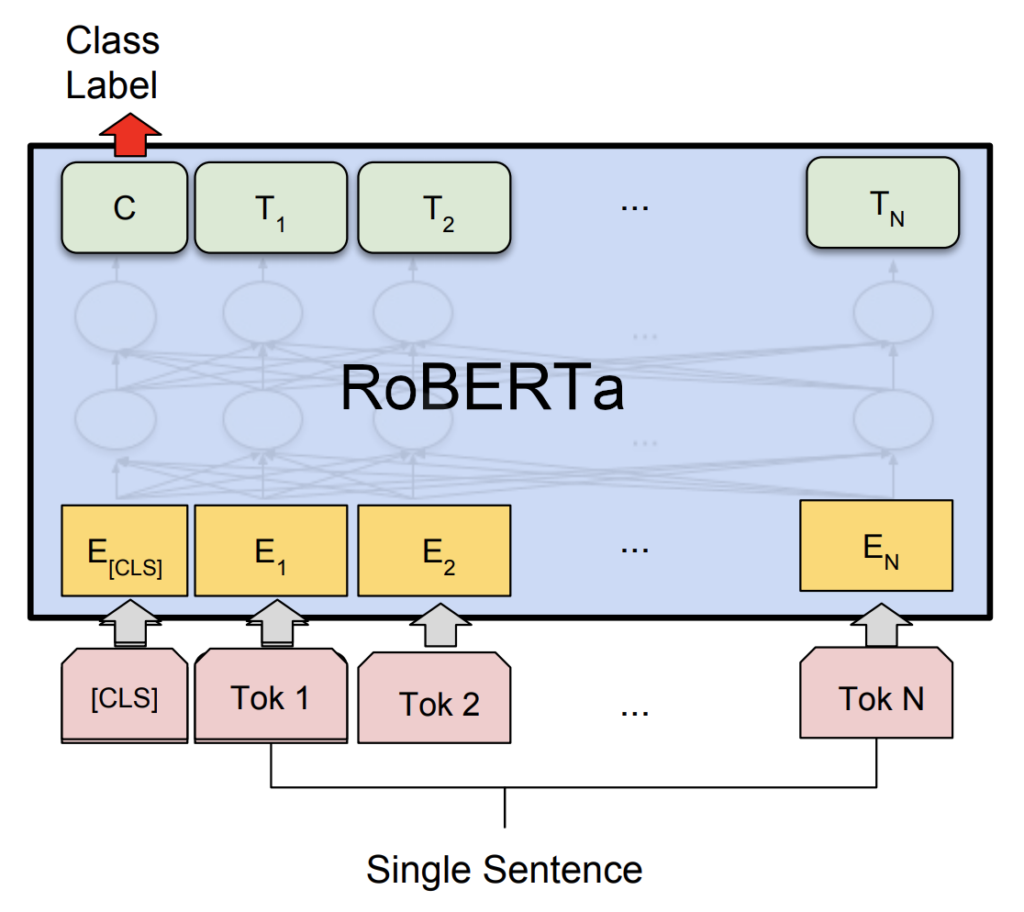
Benefits
- Overcome catastrophic forgetting
- Better performance on small datasets.
Method summary
Two components:
- An adapter trained on a task without changing the weights of the underlying language model.
- A fusion layer combining the representations from several such task adapters.
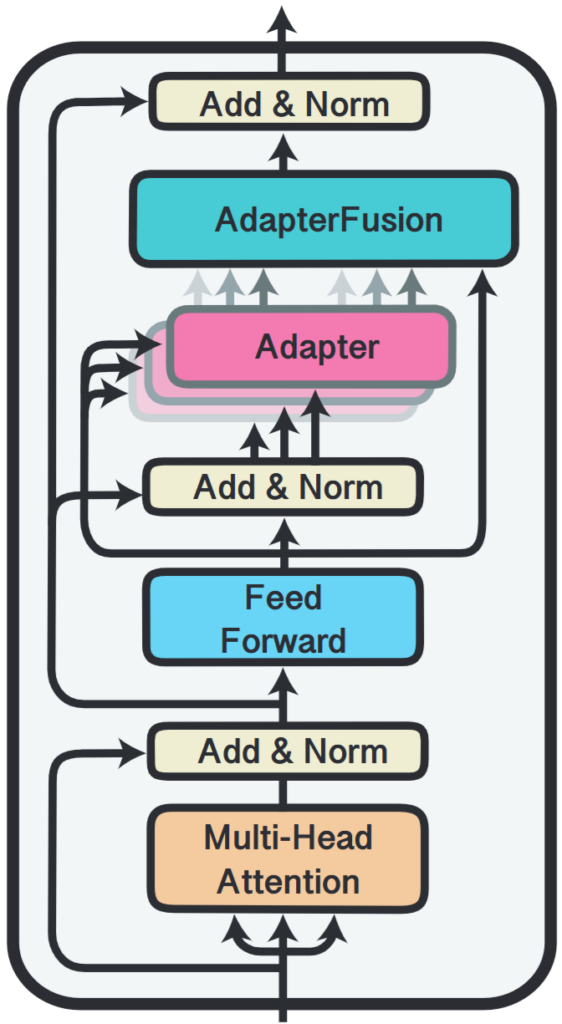
Architecture:
- AdapterFusion introduced a novel layer that fuses multiple adapters separately trained on each task, in multi-task setting. It facilitates effective fine-tuning on multi-task without modifying the backbone model weights.
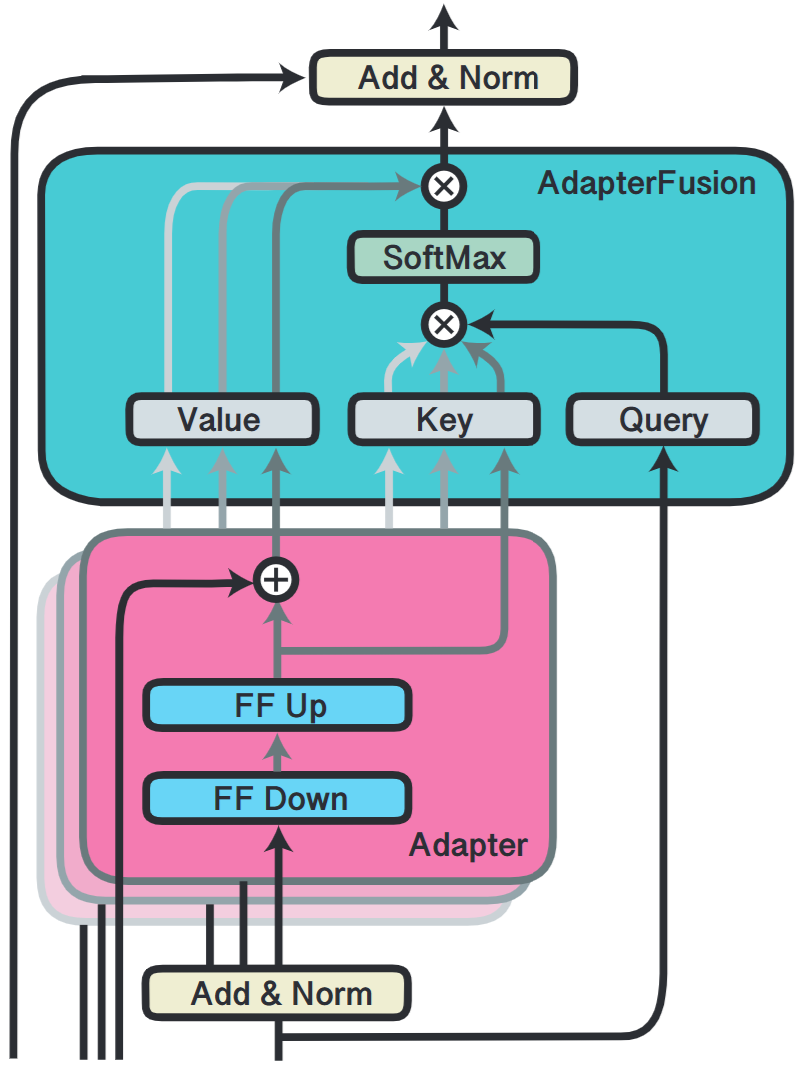
- The figure below is the AdapterFusion architecture:
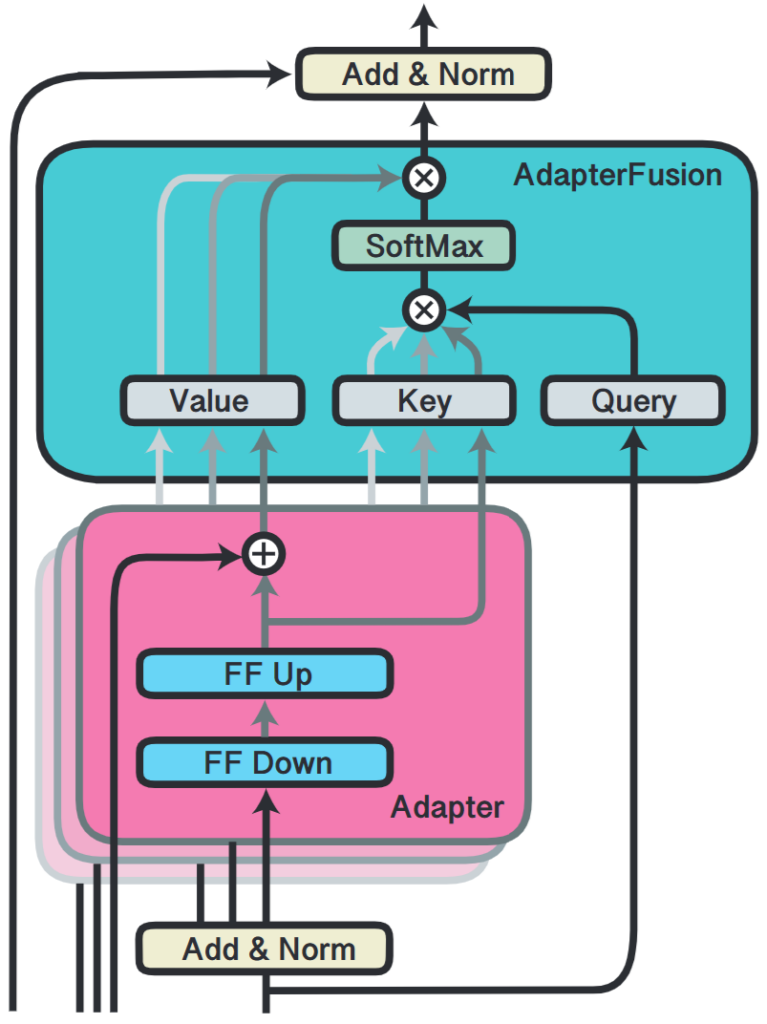
- This module takes the previous transformer layer’s output as a query.
- The output of each adapter is used as both value and key.